Kovaryans matrisi
'Kovaryans matrisi (veya varyans-kovaryans matrisi veya varyans matrisi) istatistik ve olasılık kuramı bilimlerinde veya bir rassal vektör'ün elemanları arasındaki kovaryansların bir matematik matris olarak ifade edilmesidir. Kovaryans matrisi , bir skaler-değerli rassal değişken için varyans kavramının, çoklu değişken bulunması halinde çoklu boyutlara doğal olarak genelleştirilmesidir.
Tanımlama
Eğer şu sütun vektörü içine

giren değişkenlerin her biri sonlu varyansı olan rassal değişken iseler, o halde (i, j) elemanı bir kovaryans olan matris Σ kovaryans matrisi olur:

burada

X vektöründeki iinci değişkenin beklenen değeri olur. Diğer bir deyişle, elimizde şu vardır:

Bu matrisin tersi' olan matris, yani , ters kovaryans matrisi ya da konsantrasyon matrisi veya kesinlik matrisi olarak anılır.[1] Bu "ters kovaryans matrisi"nın elemanları kısmî korelasyonlar veya kısmî varyanslara yapılan atıflarla açıklanabilirler.

Kulanılan notasyonlarda ve isimlendirmede çatışmalar
İstatistik literatüründe bu kavram için isimlendirme tek-örnek olarak degil, değişik şekillerde yapılmaktadır:
- Amerikan olasılık teoricisi William Feller'in takipcileri bu matrise X rassal vektörünün Varyans matrisi adını verirler; çünkü bu tek-boyutlu varyans kavramının doğal olarak daha yüksek boyutlarda genelleştirilmesidir.
- Diğerleri bu matris covaryans matris olarak isimlendirirler, cunku bu matrisinin skaler parcalarinin arasinda olan kovaryanslarin matrisidir.

Böylece

Ama iki vektör arasındaki karşılıklı-kovaryans için notasyon sadece tek bir standarta uyar:

Özel var notasyonu William Feller'in An Introduction to Probability Theory and Its Applications, adlı eserinde kullanılır; ama her iki alternatif notasyon da standart olarak kullanılmaktadır; bu iki değişik başta açılanıp öğrenilmekte ve anlayıp kullananlar için bir anlam karışıklığına neden olmamaktadır.
matrisi ise çok zaman varyans-kovaryans matris olarak anılır; çünkü bu matrisin diagonal elemanları varyanslardır.

Özellikleri
X p-boyutlu bir rassal degisken ve Y q-boyutlu bir rassal degisken için ve , olarak verilmisse, su temel ozellikler bulunmaktadır:


- bir positif semi-definit matrisdir.
- Eger p = q, ise o zaman
- Eğer ve birbirlerinden bağımsız iseler, o halde










burada ve rassal p×1 derecede vektör, rassal q×1 derecede vektör, ise q×1 derecede vektör, ve (q×p) dereceli matrislerdir.





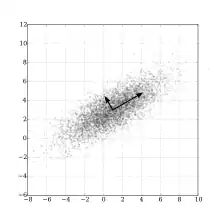
Bu kovaryans matrisi değişik alanlarda uygulamaları bulunan bir matematik araçtır. Bu matrisden bir transformayon matrisi çıkartılabilir ve bu veride bulunan bütün korelasyonların elimine edilebilmesini mümkun kılar. Bu transformasyon matrisi bularak tüm korelasyonları elimine etme analizine temel bileşenler ("principal components) analizi adı verilir.
Uygun bir kovaryans matrisi nasıl bulunur
Bazı uygulamalarda (örneğin sadece kısmen gözumlenen verilerden veri modeli kurmada) bir verilmiş belirli (gözümlenen kovaryanslardan oluşmuş) bir simetrik matrise "en yakın" kovaryans matrisi bulmak istenebilir. 2002 yılında, Higham [2] "ağırlıklı Frobenius normu" kullanarak en yakınlılık kavramını formalize etmiştir ve böylece en yakın kovaryans matrisi bulmak için gereken yöntemi vermistir.
Kestirim
Bir çoklu değişirli normal dağılım için kovaryans matrisinin maksimum-olabilirlilik kestrimcisininin elde edilmesi, belki çok zeki bir ince tranformasyon ile kolayca yapılabilir. Bakın kovaryans matrisleri kestimi
Olasılık yoğunluk fonksiyonu
Bir tane korelasyonlu rassal değişken dizisi için olasılık yoğunluk fonksiyonu, n dereceli bir Gauss-tipi vektor olan birlesik olasılık fonksiyonu olup Maksimum olabilirlik maddesinde aciklanmaktadir.

Dipnotlar
- Wasserman, Larry (2004), All of Statistics: A Concise Course in Statistical Inference (İngilizce)
- Higham, Nicholas J. ""Computing the nearest correlation matrix—a problem from finance" IMA Journal of Numerical Analysis, Cilt 22 No.3 say.329
Ayrıca bakınız
- Kovaryans matrisleri kestrimi
- Çok değişirli istatistik
- Örneklem kovaryans matrisi
- Gramian matrisi
- eigendeğer dekompozisyon
Dış kaynaklar
- İngilizce Wikipedia "Covariance matrix" maddesi (İngilizce) (Erişme:17.12.2009)
- Weisstein, Eric W., "Covariance Matrix", MathWorld--A Wolfram Web Resource26 Temmuz 2019 tarihinde Wayback Machine sitesinde arşivlendi. (İngilizce) (Erişme:17.12.2009)
- N.G. van Kampen, (1981) Stochastic processes in physics and chemistry. New York: North-Holland, (İngilizce)