Temel oran safsatası
Temel oran ihmali, temel oran yanılgısı, temel oran yanlılığı olarak da adlandırılabilen temel oran safsatası, biçimsel bir mantık safsatasıdır. Konuyla ilgili temel oran bilgisi, daha spesifik başka bilgilerle birlikte verildiğinde insan aklı, temel oran bilgisini ihmal edip sadece spesifik bilgilere odaklanarak çıkarım yapma eğilimindedir.[1] Temel oran ihmali, daha genel olan genişleme ihmalinin özel bir biçimidir.
Örnekler
Örnek 1: Hasta mıyım?
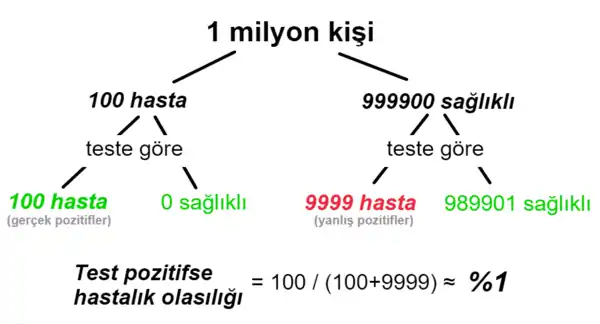
Bir sağlık sorunu nedeniyle doktora gidiyorsunuz ve size bir test yapılıyor.[2] Test, tüm hastaları hatasız bir şekilde "hasta" olarak gösterebiliyor fakat sağlıklı insanların %1'inde de hatalı olarak "hasta" sonucu veriyor. Hastalığın ise nüfustaki oranı 1/10000 (on binde bir). Testiniz pozitif çıkıyor.
Temel oranı, yani nüfustan rastgele seçilmiş bir kişinin hasta olma ya da olmama oranını hesaba katmayıp sadece testin doğruluk oranını düşünen kişiler (buna doktorlar da dahil olabilir) sizi %99 ihtimalle hasta kabul edip gerekli tedavi sürecini başlatabilirler. Siz de kendinizi %100'e yakın bir ihtimalle hasta kabul edip boşuna üzülebilirsiniz. Temel oranın etkisi hesaba katıldığında ise çok farklı bir gerçekle karşılaşılır. Test, nüfusun büyük çoğunluğunu oluşturan sağlıklı kişileri de %1 oranda hasta gösteriyor. %1 küçük bir oran gibi görünse de teste tabi tutulan nüfusun çok büyük kısmı hasta olmadığı için yine de çok sayıda insan yanlışlıkla "hasta" çıkıyor ve bu sayı gerçekten hasta olup da "hasta" çıkanlardan çok daha fazla sayıda insanı kapsıyor. Dolayısıyla test sonucu pozitif çıkan bir kişinin gerçekten hasta olma ihtimali de, bu örnekte, %1'den küçük oluyor. Bir milyon kişilik bir nüfusta durum örneklenecek olursa:
Örnek 2: Sarhoş sürücüler
Polislerin alkolmetresi ayık sürücülerin %5'ini yanlışlıkla sarhoş gösteriyor. Sarhoş sürücüleri ise hatasız olarak sarhoş gösteriyor. Her bin sürücüden biri sarhoş. Polislerin rastgele bir sürücüyü durdurup test ettiğini ve testin "sarhoş" çıktığını farz edin. Sürücüyle ilgili başka hiçbir bilgiye sahip olunmadığı varsayıldığında sürücünün gerçekten sarhoş olma olasılığı nedir?
Birçok kişi bu soruya %95 cevabını veriyor ama doğru cevap yaklaşık %2'dir. Açıklama şu şekildedir:
Ortalamada test edilen her 1000 sürücü için
- 1 sürücü sarhoştur ve bu sürücü için test sonucu %100 gerçek pozitiftir yani doğru olarak "sarhoş" sonucu çıkmıştır.
- 999 sürücü ayıktır fakat bunların %5'i için yanlış pozitif sonuç çıkmış, yani hatalı olarak "sarhoş" gösterilmişlerdir. Bu hesaplandığında 49.95 sayısı elde edilir.
Bu nedenle, test sonucu pozitif çıkan tüm sürücüler (1 + 49.95 = 50.95) arasındaki gerçekten sarhoş olan sürücülerin (1 kişi) oranı 'dir.

Yalnız dikkat edilmelidir ki bu hesaplama en başta, polislerin sürücüleri tamamen rastgele durdurduğunu varsaymaktadır; arabayı kötü kullandıkları için değil. Bu rastgeleliği bozacak bu ya da başka herhangi bir koşulun varlığı, hesaplamaya iyi araba kullanan sarhoş sürücülerin olasılığını ve kötü araba kullanan ayık sürücülerin olasılığını da katmayı gerektirecektir.
0.02'lik bu olasılık daha yöntemsel biçimde Bayes Teoremi'yle de hesaplanabilir. Amaç, alkolmetre'nin pozitif sonuç verdiği durumda sürücünün sarhoş olma olasılığını bulmaktır. Bu şöyle ifade edilebilir:

Burada "Z", alkolmetrenin pozitif sonuç göstermesi koşulunu ifade eder. Tüm ifade ise alkolmetrenin pozitif sonuç gösterdiği bir durumda sürücünün sarhoş olma ihtimalidir. Bayes teorimine göre:

Aşağıdaki bilgiler ilk paragrafta verilmişti:




Görülebileceği gibi Bayes' teoremine göre testin pozitif çıkma olasılığını ifade eden p(Z) değerine ihtiyaç var. Bu oran, testi pozitif çıkan sarhoşların olasılığı (tüm nüfusa göre) ile testi pozitif çıkan ayıkların olasılığı (tüm nüfusa göre) toplanarak bulunabilir:

buna göre

Bu oranlar Bayes' teoremine konulduğunda şu sonuç bulunur:

Örnek 3: Teröristlerin tespiti
1 milyon nüfuslu bir şehirde 100 kişinin terörist, 999900 kişinin ise terörist olmadığını farz edelim. Buna göre rastgele seçilmiş bir kişinin terörist olma temel oran olasılığı 0.0001 (10 binde 1) ve terörist olmama temel oran olasılığı 0.9999'dur (10 binde 9999). Teröristleri belirleyip yakalamak için güvenlik güçleri, şehrin çeşitli yerlerine yüz tanıma yazılımına bağlı alarm veren kameralar yerleştirsin.
Yazılımın iki hata payı da %1:
- Yanlış negatif oranı: Taradığı her 100 teröristten 1'inin yüzünü "terörist değil" olarak tanımlıyor ve alarm vermiyor.
- Yanlış pozitif oranı: Taradığı her 100 terörist olmayan kişi arasından yanlışlıkla bir kişiyi "terörist" olarak tanımlayıp alarm veriyor.
Şehirde herhangi bir kişinin alarmı tetiklediğini düşünürsek bu kişinin terörist olma olasılığı nedir? Başka bir ifadeyle, P (T|A) nedir, yani alarm tetiklenmişse bunun terörist olma olasılığı nedir?Temel oran yanılgısına kapılanlar kişinin terörist olma ihtimalini %99 olarak verecektir. Bu çıkarım ilk bakışta anlamlı gibi görünse de aslında hatalı bir akıl yürütme gerçekleşmiştir ve aşağıda görüleceği gibi bu oran %99 değil %1'e yakındır.
Yanılgı, iki farklı hata oranının karıştırılmasından kaynaklanır. "Yüzü taranan her 100 terörist için tetiklenmemiş alarm sayısı" ve "tetiklenmiş her 100 alarm için gerçek terörist sayısı" ilgisiz niceliklerdir. Birinin diğerine illa eşit olması gerekmediği gibi yakın olmaları da gerekmez. Bunu daha net görebilmek için aynı alarm sisteminin geçerli olduğu ama hiç teröristi olmayan ikinci bir şehir farz edelim. Sistem burada ilk şehirdeki gibi terörist olmayan her 100 kişiden biri için yanlışlıkla tetiklenecektir ama şehirde hiç terörist olmadığından gerçek bir terörist için hiçbir zaman tetiklenmeyecektir. Dolayısıyla, alarmın tetiklenişlerinin %100'ünde alarm yanlıştır ama "yanlış negatif" oranı hesaplanamayacaktır bile. Bu şehirde, "her 100 alarm için terörist olmayan sayısı" 100'dür ama yine de P(T|A)=%0'dır. Alarm çaldığı zaman bir teröristin tespit edilme ihtimali %0'dır.
İlk şehrin tüm nüfusunun kameranın önünden geçtiğini düşünelim. 100 teröristten 99'u alarmı tetikleyecektir. Ayrıca terörist olmayan 999900 kişiden de 9999'u alarmı yanlışlıkla tetikleyecektir (çünkü yanlış pozitif oranı: %1). Bu durumda toplamda 10098 kez (99+9999) alarm tetiklenmiş olacak ve bunların sadece 99'u gerçekten terörist olacaktır. Dolayısıyla alarm tetiklendiğinde kişinin gerçekten terörist olma olasılığı 10098'de 99'dur; bu da %1'den daha azdır.
Temel oranı ihmal safsatası bu örnek özelinde aşırı yanıltıcıdır çünkü teröristlere göre çok daha fazla terörist olmayan vardır ve yanlış pozitiflerin sayısı (terörist olarak algılanmış terörist olmayanlar) gerçek pozitiflerden (terörist olarak algılanmış gerçek teröristler) çok daha yüksektir.
Psikolojideki bulgular
Deneyler, insanların özelleşmiş bilgiler varsa, bunları, genel bilgilere tercih ettiğini gösteriyor.[3][4][5]
Bazı deneylerde, öğrencilerden varsayımsal başka öğrencilerin not ortalamalarını tahmin etmeleri istenmiştir. Not ortalamasını tahmin edecekleri spesifik bir öğrenciyle ilgili kendilerine tanımlayıcı kişisel bilgiler verildiğinde, bu bilgiler doğrudan okul performansıyla ilgili olmasa bile, not ortalaması dağılımlarıyla ilgili daha önceden verilmiş olan genel istatistiksel bilgileri reddetmeye meyilli oldukları gözlenmiştir.[4] Bu bulgu, okula giriş süreçlerindeki mülakatların iptal edilmesi için bir argüman olarak bile kullanılmıştır çünkü mülakatı yapan kişiler doğru adayları temel istatistiksel çıkarımlardan daha başarılı olarak seçememektedir.
Psikolog Daniel Kahneman ve Amos Tversky bu bulguyu "temsil edilebilirlik" olarak adlandırılan daha basit bir kuralla ya da "höristik"le[6] açıklamayı denedi. Bir olasılıkla ya da bir sebep-sonuçla ilgili birçok yargının, bir şeyin başka bir şeyi ya da kategoriyi ne derece temsil ettiğine bağlı olarak biçimlendiğini öne sürdüler.[4] Kahneman temel oran ihmalini genişleme ihmalinin özel bir biçimi olarak görür.[7] Richard Nisbett, "temel atıf hatası" gibi bazı atıf yanlılıklarının temel oran safsatasının bir örneği olduğunu ileri sürdü: İnsanlar, benzer durumlarda başkalarının nasıl davrandığına yönelik olarak "mutabakat bilgisi"ni ("temel oran"ı) kullanmıyor, bunun yerine daha basit mizaci atıfları[8] tercih ediyordu.[9]
İnsanların hangi koşullar altında temel oran bilgilerini dikkate aldıkları ya da almadıkları üzerine psikolojide tartışılmaktadır.[10][11] "Kestirmeler ve yanlılıklar" alanındaki araştırmacılar, insanların temel oranları ihmal etmeye ve Bayes' teoremi gibi olasılıksal akıl yürütmenin çeşitli normlarını görmezden gelmeye meyilli olduklarını gösteren deneysel bulgular olduğunu vurguluyor. Bu araştırma alanından çıkan sonuç, insanın olasılıksal düşünmesinin kökten kusurlu ve hatalara açık oluşuydu.[12] Başka araştırmacılar ise bilişsel süreçlerle bilgi formatları arasındaki bağlantıya vurgu yaptı ve bu tarz sonuçların genellikle garanti edilemeyeceğini ileri sürdü.[13][14]
Yukarıdaki "Örnek 1"i tekrar ele alalım. İstenen çıkarım, rastgele seçilen bir sürücünün alkolmetre testi pozitif ise bu kişinin sarhoş olma olasılığını ne olduğuydu. Bu olasılık yukarıda gösterildiği gibi Bayes' teoremiyle hesaplanabilir fakat aynı bilgiyi sunmanın farklı yolları da var. Aslında tamamen aynı problemin farklı bir ifadesine bakalım:
- 1000 sürücüden 1'i sarhoş. Alkolmetre sarhol birinde kesinlikle yanılmıyor. Sarhoş olmayan her 999 kişiden 50 kişi de alkolmetre yanılıyor ve sarhoşluk gösteriyor. Bu durumda polisin rastgele birini durdurup test uyguladığını varsayalım. Alet "sarhoş" gösteriyor. Bu kişiyle ilgili başka bilgimizin olmadığını varsayarsak gerçekten sarhoş olma ihtimali ne kadardır?
Bu örnekte, ilgili sayısal bilgi -p(sarhoş), p(H|sarhoş), p(H|ayık)- belirli bir referans sınıfına ilişkin doğal frekanslar olarak sunulmuştur. Deneysel çalışmalar, bilgilerin bu şekilde sunulmasının sıradan insanların[14] ve bilim insanlarının[15] temel oran ihmalinin üstesinden gelmelerine yardımcı olarak çıkarımlarının Bayes' kuralıyla daha fazla uyuştuğunu gösteriyor. Bunun bir sonucu olarak, Cochrane gibi kurumlar sağlık istatistiklerinin paylaşımında bu sunuş biçiminin kullanılmasını öneriyor.[16] İnsanlara, bu tarz bayesçi akıl yürütme problemlerini doğal frekans biçimlerine çevirmeyi öğretmek, onlara sadece olasılıkları ve yüzdeleri Bayes' teoremine yerleştirmeyi öğretmekten daha etkili.[17] Doğal frekansların görsel temsillerinin de insanların daha doğru çıkarımlar yapmalarına yardımcı olduğu gösterildi.[17][18][19]
Doğal frekans biçimleri neden yararlı? Önemli bir nedeni, gerekli hesaplamaları basitleştirdiği için istenen çıkarımları kolaylaştırması. İlk örnekteki p(sarhos|H) olasılığının alternatif bir hesaplanışında bu görülebilir:

Burada N(sarhos ∩ H), sarhoş olup pozitif alkolmetre sonucu alan sürücelerin sayısını belirtiyor. N(D), pozitif alkolmetre sonucu çıkan tüm testlerin sayısını belirtiyor. Bu denklemin yukarıdakine denk oluşu, olasılık teorisinin aksiyomlarından çıkarsanıyor; buna göre N(sarhoş ∩ H) = N × p (H | sarhoş) × p (sarhoş). Önemli bir nokta şu ki, bu denkelm matematiksel olarak Bayes' kuralına denk olsa da psikolojik olarak denk değil. Doğal frekansların kullanımı çıkarımı basitleştiriyor çünkü gereken matematiksel hem işlem normalize edilmiş kesirler (olasılıklar gibi) yerine doğal sayılar üzerinde yapılabiliyor hem yanlış pozitiflerin fazlalığını açık ediyor hem de doğal frekanslar bir "iç içe oturmuş yapı" sergiliyor.[20][21]
Her frekans biçiminin bayesçi akıl yürütmeyi kolaylaştırmadığını ifade etmek önemli.[21][22] Doğal frekanslar, temel oran bilgisini (örn. rastgele bir sürücü örneklemindeki sarhoş sürücü sayısı) koruyan doğal örneklemeden[23] çıkan frekans bilgisine işaret eder. Bu, temel oranların a priori sabitlenmiş olduğu (örn. bilimsel deneyler) sistematik örneklemeden farklıdır. İkinci durumda, sonsal p(sarhos|H) olasılığını, hem sarhoş olan hem de testi pozitif çıkan sürücülerin sayısını testi pozitif çıkan tüm sürücülerin sayısıyla karşılaştırarak çıkarsamak mümkün değildir çünkü temel oran bilgisi korunmamıştır ve Bayes' teoremi kullanılarak doğrudan yeniden elde edilmelidir.
Ayrıca bakınız
- Bayesci olasılık
- Data dredging16 Aralık 2017 tarihinde Wayback Machine sitesinde arşivlendi.
- False positive paradox7 Ocak 2018 tarihinde Wayback Machine sitesinde arşivlendi.
- Inductive argument22 Aralık 2017 tarihinde Wayback Machine sitesinde arşivlendi.
- List of cognitive biases21 Aralık 2017 tarihinde Wayback Machine sitesinde arşivlendi.
- Misleading vividness13 Aralık 2017 tarihinde Wayback Machine sitesinde arşivlendi.
- Prosecutor's fallacy28 Ocak 2018 tarihinde Wayback Machine sitesinde arşivlendi.
- Stereotype14 Aralık 2017 tarihinde Wayback Machine sitesinde arşivlendi.
Kaynakça
Bu maddenin yazılmasında aynı maddenin İngilizce Wikipedia'daki versiyonundan yararlanılmıştır.24 Aralık 2017 tarihinde Wayback Machine sitesinde arşivlendi.
- "Logical Fallacy: The Base Rate Fallacy". Fallacyfiles.org. 13 Aralık 2017 tarihinde kaynağından arşivlendi. Erişim tarihi: 15 Haziran 2013.
- "Arşivlenmiş kopya". 26 Aralık 2017 tarihinde kaynağından arşivlendi. Erişim tarihi: 26 Aralık 2017.
- Bar-Hillel, Maya (1980). "The base-rate fallacy in probability judgments". Acta Psychologica. Cilt 44. ss. 211-233. doi:10.1016/0001-6918(80)90046-3.
- Kahneman, Daniel; Amos Tversky (1973). "On the psychology of prediction". Psychological Review. Cilt 80. ss. 237-251. doi:10.1037/h0034747.
- Kahneman, Daniel; Amos Tversky (1985). "Evidential impact of base rates". Daniel Kahneman, Paul Slovic & Amos Tversky (Eds.) (Ed.). Judgment under uncertainty: Heuristics and biases. ss. 153-160.
- "Arşivlenmiş kopya". 9 Aralık 2017 tarihinde kaynağından arşivlendi. Erişim tarihi: 27 Aralık 2017.
- Kahneman, Daniel (2000). "Evaluation by moments, past and future". Daniel Kahneman and Amos Tversky (Eds.) (Ed.). Choices, Values and Frames.
- "Arşivlenmiş kopya". 28 Temmuz 2017 tarihinde kaynağından arşivlendi. Erişim tarihi: 22 Aralık 2017.
- Nisbett, Richard E.; E. Borgida; R. Crandall; H. Reed (1976). "Popular induction: Information is not always informative". J. S. Carroll & J. W. Payne (Eds.) (Ed.). Cognition and social behavior. 2. ss. 227-236.
- Koehler, J. J. (2010). "The base rate fallacy reconsidered: Descriptive, normative, and methodological challenges". Behavioral and Brain Sciences. Cilt 19. s. 1. doi:10.1017/S0140525X00041157.
- Barbey, A. K.; Sloman, S. A. (2007). "Base-rate respect: From ecological rationality to dual processes". Behavioral and Brain Sciences. 30 (3). ss. 241-254; discussion 255-297. doi:10.1017/S0140525X07001653. PMID 17963533.
- Tversky, A.; Kahneman, D. (1974). "Judgment under Uncertainty: Heuristics and Biases". Science. 185 (4157). ss. 1124-1131. doi:10.1126/science.185.4157.1124. PMID 17835457.
- Cosmides, Leda; John Tooby (1996). "Are humans good intuitive statisticians after all? Rethinking some conclusions of the literature on judgment under uncertainty". Cognition. Cilt 58. ss. 1-73. doi:10.1016/0010-0277(95)00664-8.
- Gigerenzer, G.; Hoffrage, U. (1995). "How to improve Bayesian reasoning without instruction: Frequency formats". Psychological Review. 102 (4). s. 684. doi:10.1037/0033-295X.102.4.684.
- Hoffrage, U.; Lindsey, S.; Hertwig, R.; Gigerenzer, G. (2000). "Medicine: Communicating Statistical Information". Science. 290 (5500). ss. 2261-2262. doi:10.1126/science.290.5500.2261. PMID 11188724.
- Akl, E. A.; Oxman, A. D.; Herrin, J.; Vist, G. E.; Terrenato, I.; Sperati, F.; Costiniuk, C.; Blank, D.; Schünemann, H. (2011). Schünemann, Holger (Ed.). "Using alternative statistical formats for presenting risks and risk reductions". The Cochrane Library. doi:10.1002/14651858.CD006776.pub2.
- Sedlmeier, P.; Gigerenzer, G. (2001). "Teaching Bayesian reasoning in less than two hours". Journal of Experimental Psychology: General. 130 (3). s. 380. doi:10.1037/0096-3445.130.3.380.
- Brase, G. L. (2009). "Pictorial representations in statistical reasoning". Applied Cognitive Psychology. 23 (3). ss. 369-381. doi:10.1002/acp.1460.
- Edwards, A.; Elwyn, G.; Mulley, A. (2002). "Explaining risks: Turning numerical data into meaningful pictures". BMJ. 324 (7341). ss. 827-830. doi:10.1136/bmj.324.7341.827. PMC 1122766 $2. PMID 11934777.
- Girotto, V.; Gonzalez, M. (2001). "Solving probabilistic and statistical problems: A matter of information structure and question form". Cognition. 78 (3). ss. 247-276. doi:10.1016/S0010-0277(00)00133-5. PMID 11124351.
- Hoffrage, U.; Gigerenzer, G.; Krauss, S.; Martignon, L. (2002). "Representation facilitates reasoning: What natural frequencies are and what they are not". Cognition. 84 (3). ss. 343-352. doi:10.1016/S0010-0277(02)00050-1. PMID 12044739.
- Gigerenzer, G.; Hoffrage, U. (1999). "Overcoming difficulties in Bayesian reasoning: A reply to Lewis and Keren (1999) and Mellers and McGraw (1999)". Psychological Review. 106 (2). s. 425. doi:10.1037/0033-295X.106.2.425.
- Kleiter, G. D. (1994). "Natural Sampling: Rationality without Base Rates". Contributions to Mathematical Psychology, Psychometrics, and Methodology. Recent Research in Psychology. ss. 375-388. doi:10.1007/978-1-4612-4308-3_27. ISBN 978-0-387-94169-1.
Dış bağlantılar
- Hayvanlara eziyet ve seri katiller; Yalansavar makalesi2 Ocak 2018 tarihinde Wayback Machine sitesinde arşivlendi.
- Her sakallıyı baban sanma: Temel oranı ihmal yanılgısı; Yalansavar makalesi26 Aralık 2017 tarihinde Wayback Machine sitesinde arşivlendi.
- The Base Rate Fallacy13 Aralık 2017 tarihinde Wayback Machine sitesinde arşivlendi. The Fallacy Files
- Psychology of Intelligence Analysis: Base Rate Fallacy27 Şubat 2018 tarihinde Wayback Machine sitesinde arşivlendi.
- The base rate fallacy explained visually15 Kasım 2018 tarihinde Wayback Machine sitesinde arşivlendi. (Video)
- Interactive page for visualizing statistical information and Bayesian inference problems30 Ekim 2016 tarihinde Wayback Machine sitesinde arşivlendi.
- Current ‘best practice’ for communicating probabilities in health according to the International Patient Decision Aid Standards (IPDAS) Collaboration9 Ağustos 2017 tarihinde Wayback Machine sitesinde arşivlendi.